

Throughout history, language has been the most effective means of communication. Since the early days of artificial intelligence, computer scientists have dreamed of being able to comprehend and analyze it. The advancements in this field during the last few decades have been remarkable. Simple systems built on rigid grammatical rules gave way to sophisticated tools like GPT-5, which can now produce articles, respond to queries, translate languages, and even compose poetry. These systems, commonly referred to as language models, are influencing how people communicate with computers.
From rule-based systems to statistical techniques, neural networks, and eventually the state-of-the-art transformer models that characterize our current state, this article takes you on a journey through their history.
Early Rule-Based Systems
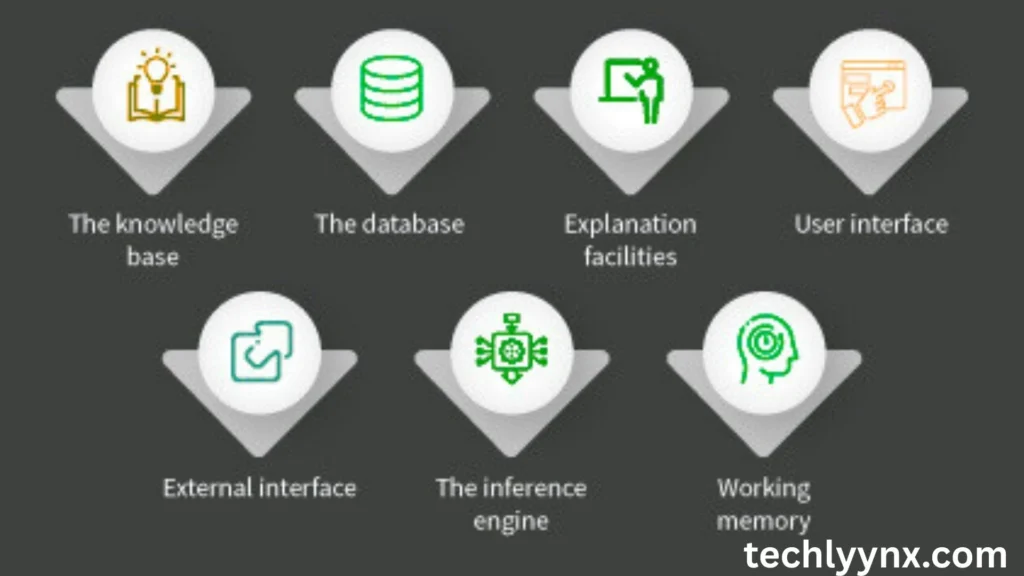
The first attempts to teach computers to understand language were rule-based and took place in the 1950s and 1960s. The syntax and meaning rules were manually written out in these systems by linguists and programmers. For instance, you had to specify rules for subjects, verbs, and objects if you wanted the system to identify a sentence like “The cat sat on the mat.”
Rule-based systems excelled in accuracy. The computer produced accurate results if you followed the instructions precisely. These systems did have significant flaws, though. They were unable to deal with the slang, ambiguity, exceptions, and mistakes that are inherent in human language. The systems became complicated and challenging to scale as new terms and concepts necessitated additional rules.
Despite their limitations, rule-based systems played an important role. They proved that computers could deal with human language, at least in controlled environments, and they laid the foundation for future progress.
Growth of Statistical Language Models
Researchers discovered that depending solely on set grammar rules was insufficient by the 1980s and 1990s. They started utilizing statistics instead. Instead of relying solely on rules created by humans, statistical language models learned from data.
For example, a system can determine the likelihood that one word will follow another if it is fed millions of sentences. This indicates that it has a certain degree of accuracy in predicting the subsequent word in a series. These versions offered versatility and flexibility. They performed well in early machine translation, speech recognition, and predictive text applications.
Still, statistical models had their challenges. They required huge datasets, and even then, they often failed to capture the deeper meaning of words. For example, they could predict that “bank” is likely to be followed by “account” but might not understand whether “bank” means a financial institution or the side of a river.
Nevertheless, this stage marked the beginning of systems that could handle larger volumes of text and operate in real-world situations.
Neural Networks and Deep Learning in Language Models
The emergence of deep learning and neural networks in the 2000s marked the next revolution. In contrast to statistical models, which were mostly based on probabilities, neural networks discovered patterns in data that were overlooked. They used layers of interconnected “neurons” that processed information step-by-step, drawing inspiration from the organization of the human brain.
Word embeddings like Word2Vec were among the first innovations. These technologies enabled computers to recognize word associations by representing words as vectors in mathematical space. The model might comprehend, for instance, that “king” and “queen” are related in the same manner as “man” and “woman.”
Later, recurrent neural networks (RNNs) and long short-term memory networks (LSTMs) improved the ability of models to understand sequences of text. However, they still struggled with very long sentences or paragraphs.
The real breakthrough came with transformers, introduced in 2017. Transformers allowed models to process entire sequences of words at once rather than one at a time. This architecture unlocked massive improvements in performance and efficiency.
GPT-5 and the Future of Language Models

The introduction of transformer-based models led to the development of GPT-2, GPT-3, GPT-4, and now GPT-5 systems. These versions are not just larger, but also essentially more powerful. For example, GPT-5 is able to produce language that feels surprisingly human. It can write code, write stories, summarize articles, provide answers to queries, and even help with scientific studies.
GPT-5’s training on large volumes of data and its comprehension of context in lengthy text sections are what give it its strength. It does more than merely use basic probability to anticipate the following word, in contrast to previous models. Rather, it develops a sophisticated comprehension of style, tone, and meaning.
Of course, challenges remain. Language models like GPT-5 can sometimes produce incorrect or biased information, depending on the data they were trained on. This has raised important ethical questions about reliability, transparency, and misuse. Researchers are now focusing on making these systems safer, more accountable, and more inclusive.
Looking forward, the future of language models points toward multimodal systems that go beyond text. GPT-5 is already part of this movement, handling not only written words but also images, code, and potentially audio and video. Imagine an AI assistant that can read a textbook, explain it to you, generate diagrams, and answer follow-up questions—all in one seamless interaction.
Impact on Society and Beyond
The impact of these advancements is already visible across industries. In healthcare, language models help analyze patient records and assist in diagnosing diseases. In business, they draft reports, generate marketing content, and provide customer support. In education, they serve as tutors, helping students learn languages, math, and science.
At the same time, the rise of these systems raises serious concerns. Will they replace human jobs? How do we prevent misinformation generated by AI? Can we ensure privacy when these models are trained on massive amounts of text from the internet?
Governments and institutions are now debating regulations to strike a balance between innovation and responsibility. The goal is to maximize the benefits of language models while minimizing their risks.
In conclusion,
The development of language models, from the early days of strict rule-based systems to the state-of-the-art capabilities of GPT-5, mirrors the larger narrative of artificial intelligence. We are getting closer to creating machines that can comprehend and interact with people in natural ways with each new development—rules, statistics, neural networks, transformers, etc.
These systems will keep developing as we go forward, growing not only more intelligent but also more moral, dependable, and adaptable. Language models are at the core of the idea of smooth human-machine interaction, which is no longer just science fiction but is actually happening.