
Artificial intelligence has transformed the way we interact with information. From chatbots to virtual assistants, natural language processing (NLP) models have grown smarter, but they still face a persistent challenge—hallucinations and limited awareness of facts beyond their training data. This is where retrieval-augmented generation for knowledge-intensive NLP tasks comes into play.
Retrieval-augmented generation (RAG) integrates the advantages of generative AI models and information retrieval systems, rather than depending exclusively on pre-trained parameters. By enabling models to “look up” pertinent information in real time, this method increases accuracy, lowers false information, and makes context-aware AI possible for intricate decision-making.
Why Traditional NLP Models Struggle with Knowledge-Intensive Tasks
Massive datasets are used to train large language models (LLMs), such as GPT or BERT. They still have certain shortcomings, though:
- Static Knowledge Base: Without expensive retraining, they are unable to keep up with the most recent information after being trained.
- Hallucinations: Models occasionally produce comments that are fluid but inaccurate in terms of facts.
- Domain-Specific Deficits: Training data may not be enough in specialist fields like finance, law, or medicine.
These drawbacks are crucial for knowledge-intensive NLP jobs (such as analyzing legal documents, using scientific reasoning, or responding to technical inquiries). Instead of guesswork, users need answers that are trustworthy and supported by evidence.
Retrieval-augmented generation excels in this situation.
What is Retrieval-Augmented Generation (RAG)?
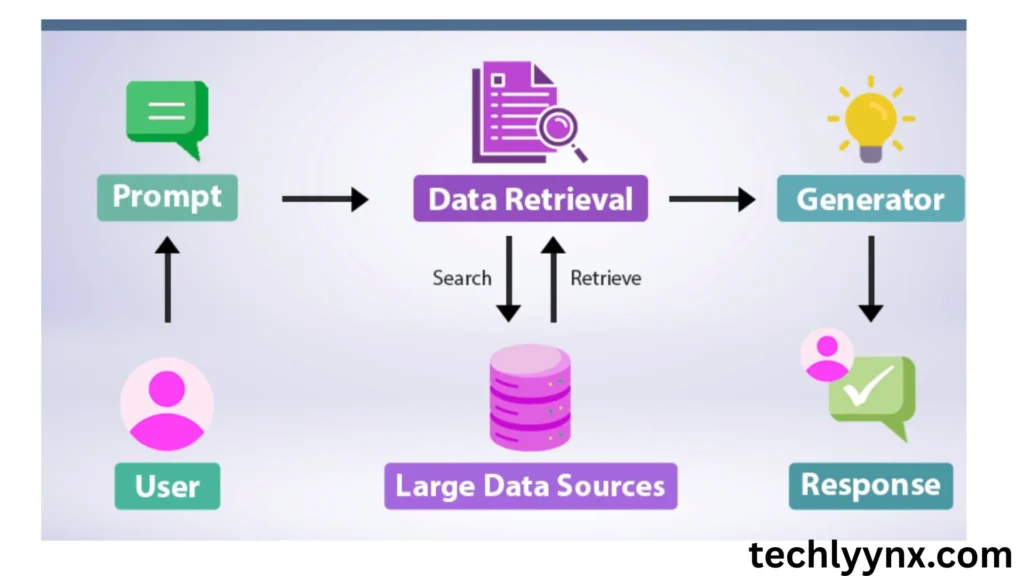
Two essential elements are combined in the hybrid AI architecture known as retrieval-augmented generation:
An information retrieval system, or retriever, looks through an external database, knowledge graph, or search index to find and retrieve pertinent documents or knowledge snippets.
The language model generator creates precise, fluid, and well-founded answers by using the context that has been retrieved.
To put it simply, imagine RAG as an AI student who not only retains the knowledge it has learned but also looks up information from a library before responding to challenging queries.
How Retrieval-Augmented Generation Works
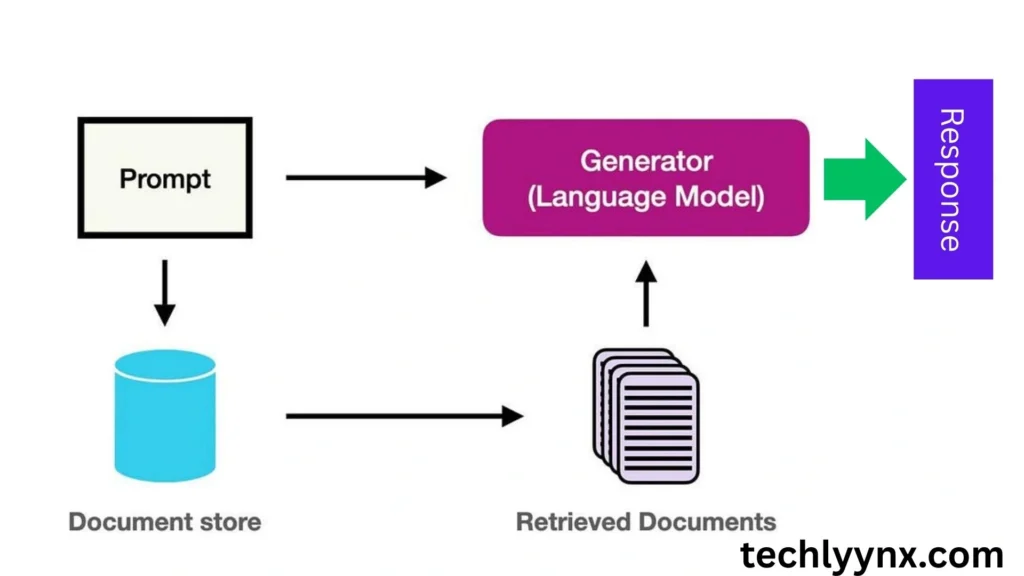
This is a detailed explanation of the RAG procedure:
- User Inquiry: One poses a query, such as “What are the health risks of microplastics?”
- Phase of Retrieval: To find the most pertinent texts, the retriever searches a knowledge base (Wikipedia, PubMed, enterprise papers, etc.).
- The addition of retrieved sections as input context is known as augmentation.
- Phase of Generation: After processing the question and the context it has retrieved, the language model produces a fact-based response.
The output is guaranteed to be factually sound and linguistically coherent thanks to its architecture.
Applications of Retrieval-Augmented Generation in Knowledge-Intensive NLP Tasks
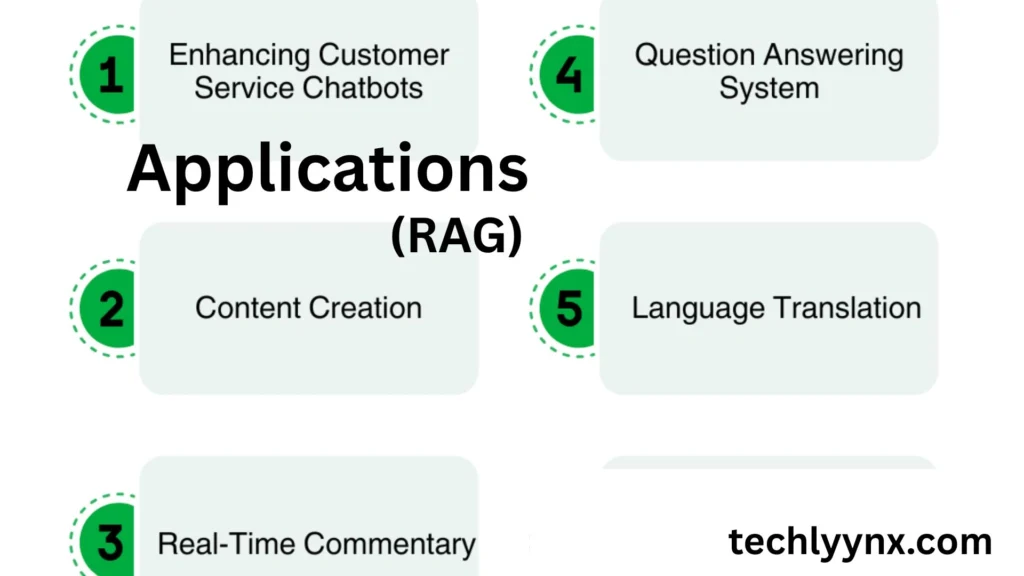
Question Answering Systems
RAG models excel in open-domain question answering, especially when users expect answers backed by references. For example, a medical chatbot can cite PubMed articles while answering health queries.
2. Enterprise Search and Knowledge Management
Companies can deploy RAG to search internal knowledge bases, policies, or product manuals—helping employees find precise answers instead of wading through lengthy documents.
3. Scientific Research Support
Researchers can query RAG-powered tools to summarize scientific literature, compare findings, and highlight relevant studies for ongoing work.
4. Legal and Regulatory Analysis
Lawyers and compliance officers benefit from RAG models that can quickly retrieve and explain relevant case law, regulations, or contractual terms.
5. Customer Support Chatbots
Instead of generic answers, chatbots augmented with retrieval capabilities can provide customers with detailed, evidence-based troubleshooting steps, citing manuals or FAQs.
Benefits of Retrieval-Augmented Generation
- Accuracy and Reliability: RAG lessens hallucinations by establishing answers in outside papers.
- Current Knowledge: Retrieval systems have the ability to draw in the most recent data, in contrast to static LLMs.
- Domain Adaptability: Businesses are able to create unique retrievers that are connected to their proprietary databases.
- Transparency: By including sources with generated text, several RAG systems boost user confidence.
- Efficiency: Organizations merely need to update knowledge databases rather than retraining models.
Challenges of Retrieval-Augmented Generation

RAG is promising, but it also has certain challenges:
Retrieval Quality: The generator’s output can still be problematic if the retriever returns documents that are low-quality or irrelevant.
Latency Problems: Real-time apps may experience lag when retrieving external documents.
Scaling Databases: It takes resources to maintain and update large external knowledge bases.
Bias in Retrieved Sources: The system may magnify biased data if it exists in the knowledge base itself.
Evaluation Difficulty: It is still difficult to measure factual accuracy in open-domain jobs.
Real-World Examples of RAG Systems

One of the earliest real-world applications was Meta’s RAG Model, which combined a retriever with a BART-based generator.
ChatGPT with Browsing/Retrieval Plugins: Improved retrieval capabilities provide more precise responses with references.
Perplexity AI is a conversational search engine that provides cited answers through RAG-like principles.
Enterprise Knowledge Assistants: A lot of businesses are developing internal domain-specific RAG systems.
Future of Retrieval-Augmented Generation in NLP
The next phase of retrieval-augmented generation for knowledge-intensive NLP tasks will likely see tighter integration between retrieval and generation components. Key directions include:
- Neuro-Symbolic Integration – Combining symbolic reasoning with neural retrieval for deeper logical reasoning.
- Multimodal RAG – Retrieval across not only text but also images, graphs, and videos.
- Personalized Retrieval – Tailoring results to individual user profiles and preferences.
- Edge AI RAG Systems – Running retrieval-augmented pipelines directly on local devices for privacy-sensitive domains.
As LLMs become more mainstream, RAG will be essential to build trustworthy, transparent, and domain-specific AI applications.
Conclusion
In the era of information overload, AI must not only generate fluent language but also ground its answers in verifiable knowledge. That’s why retrieval-augmented generation for knowledge-intensive NLP tasks is emerging as a game-changer. By blending information retrieval with generative AI, RAG ensures responses that are both accurate and contextually rich.
For industries ranging from healthcare and law to research and customer support, retrieval-augmented generation is more than just a trend—it’s a cornerstone of the next generation of knowledge-aware NLP systems.